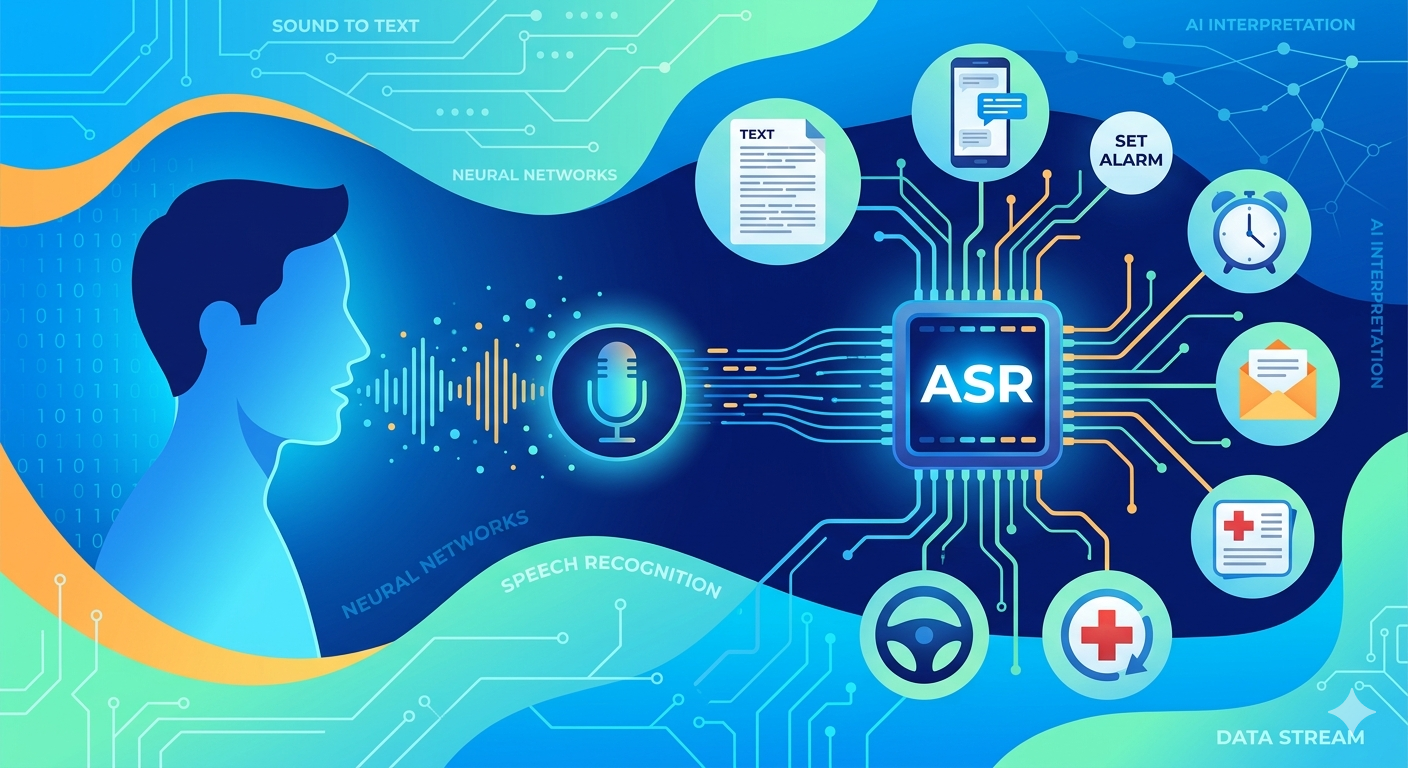
In the modern digital landscape, the way we communicate with technology has shifted from tactile inputs to vocal commands. At the heart of this revolution lies automatic speech recognition, a sophisticated field of computer science that enables machines to identify and process human language. Whether you are dictating a text message, asking a virtual assistant for the weather, or utilizing real-time captions during a global webinar, you are engaging with asr systems. This technology has evolved from simple pattern matching to complex neural networks that can understand nuances, dialects, and intent with startling precision.
Understanding what is asr requires looking at the intersection of linguistics, mathematics, and artificial intelligence. Essentially, asr meaning refers to the capability of a program to process a human voice into a written format. This is not merely a “recorder” but a sophisticated interpreter that must filter out background noise, account for unique vocal characteristics, and predict the next word in a sentence based on context. As we continue to integrate speech recognition technology into our daily lives, from automotive systems to healthcare documentation, the underlying models become increasingly essential for global accessibility and productivity.
The transition from traditional typing to automated speech recognition represents one of the most significant leaps in accessibility in the last century. For individuals with motor impairments or those who require hands-free operation, speech recognition is more than a convenience—it is a vital bridge to the digital world. This guide will explore the intricate mechanics of how these systems function, the various asr model architectures currently in use, and how businesses can leverage asr software to streamline their operations and enhance user experiences.
What is Automatic Speech Recognition?
To provide a clear definition of asr, we must look at it as a multi-stage process of translation. Automatic speech recognition is the use of hardware and software-based techniques to identify and process human voice. It is often referred to as “speech-to-text” or automated speech. While the terms are frequently used interchangeably, asr specifically focuses on the “recognition” aspect—ensuring the machine correctly identifies the phonemes and words spoken—whereas transcription is the broader act of documenting that speech.
When asking what does asr stand for, the “Automatic” part is crucial. Unlike manual transcription where a human listens and types, an asr system operates in real-time or near-real-time without human intervention. This automation is powered by a transcription model that has been trained on thousands of hours of audio data. These models allow the software to recognize patterns in sound waves and map them to corresponding linguistic units. Today, automated speech recognition ai has reached a point where it can often match or even exceed human accuracy in controlled environments.
The asr meaning in the context of modern AI also involves “Natural Language Processing” (NLP). While asr handles the conversion of sound to text, NLP handles the “understanding” of that text. This combination is what allows a speech recognition system to not only transcribe your words but also execute commands. For instance, if you tell your phone to “Set an alarm,” the asr identifies the words, and the AI interprets the intent. This synergy is what makes automatic speech recognition asr one of the most dynamic fields in technology today.

How Does ASR Transcription Work? The Step-by-Step Process
Understanding how does asr work requires a look at the journey of a sound wave from the human mouth to the computer screen. This process is incredibly fast, often occurring in milliseconds. It begins with the “Acoustic Analysis,” where the microphone captures the vibrations of your voice and converts them into an electrical signal. This analog signal is then digitized, turning the smooth waves of sound into discrete data points that an asr model can analyze.
Once the signal is digitized, the asr software performs “Feature Extraction.” The system breaks the audio into tiny segments, usually around 10 to 20 milliseconds long. In each segment, it looks for specific “features” such as pitch, volume, and frequency. These features are then compared against an “Acoustic Model.” This model is a massive database of statistical representations of sounds. It helps the asr system determine if a specific sound segment represents a “b,” a “p,” or any other phoneme (the smallest unit of sound in a language).
After the acoustic model identifies potential phonemes, the “Language Model” takes over. This is where the automated speech recognition software uses probability to determine the most likely word being spoken. For example, if the acoustic model hears something that could be “bear” or “bare,” the language model looks at the surrounding words. If the sentence is “The ___ ate the honey,” the system knows with high probability that the word is “bear.” Finally, the transcription model outputs the most likely string of text, completing the automatic talking to digital text conversion.
The Architecture of a Modern ASR System
A robust asr system is comprised of several moving parts that work in tandem to ensure high accuracy. At the base is the “Signal Processing” layer, which is responsible for noise cancellation and echo suppression. This is vital because automated speech recognition often takes place in noisy environments like moving cars or busy offices. If the signal processing fails, the asr model receives “dirty” data, which significantly increases the error rate.
The heart of the technology is the asr model architecture itself. Historically, these were built using Hidden Markov Models (HMMs), which relied on simple statistical probabilities. However, modern automated speech recognition ai uses “Deep Neural Networks” (DNNs). These neural networks are modeled after the human brain, with layers of artificial neurons that can learn complex patterns. Specifically, Recurrent Neural Networks (RNNs) and “Transformers” are now the gold standard for speech recognition technology, as they are excellent at processing sequences of data where the order of the words matters immensely.
Another critical component is the “Lexicon” or the dictionary. This is a mapping of words to their phonetic pronunciations. When the asr software identifies a sequence of phonemes, it checks the lexicon to see if that sequence forms a valid word in the target language. Sophisticated asr systems also include specialized vocabularies for different industries. For example, an asr automated speech recognition system designed for a hospital will have a lexicon filled with medical terminology, while one for a law firm will be optimized for legal jargon.
Key Technologies Powering Automatic Speech Recognition
The rapid advancement of automated speech recognition is directly linked to the rise of big data and high-performance computing. To train a high-quality asr model, developers need access to “Labeled Audio Data”—recordings of people talking along with the correct transcriptions. The more diverse this data is (including different accents, ages, and genders), the better the speech recognition technology becomes at handling real-world users. This is why major tech companies are constantly refining their asr software using the data they collect from millions of voice interactions.
“End-to-End” (E2E) models represent a major shift in how does asr work. In older systems, the acoustic and language models were trained separately and then joined together. In an E2E asr system, a single neural network is trained to take audio in and put text out. This simplifies the development process and often leads to higher accuracy because the system can optimize the entire pipeline at once. This technology is the backbone of the most advanced automatic speech recognition software available today, providing near-human levels of transcription in many languages.
Another significant technological trend is automatic speech recognition on-device. Traditionally, asr required sending your audio to a powerful server in the cloud for processing. However, as mobile processors have become more powerful, much of this work can now happen directly on your phone or laptop. This provides two massive benefits: speed and privacy. Since the audio never leaves your device, your private conversations remain secure. This asr automatic speech recognition capability is now a standard feature in high-end smartphones and smart home devices.
Accuracy, Bias, and the Challenges of Speech Recognition
While automatic speech recognition has come a long way, it is not perfect. The primary metric for measuring the quality of an asr model is the “Word Error Rate” (WER). WER is calculated by taking the number of substitutions, deletions, and insertions made by the system and dividing them by the total number of words spoken. A lower WER indicates a more accurate asr system.
Currently, high-quality asr transcription services aim for a WER of under 5% in clean audio conditions, which is roughly equivalent to human performance.
One of the biggest hurdles for speech recognition is “Acoustic Variability.” This includes background noise, room reverberation, and the quality of the microphone. If you are using asr software in a crowded cafe, the system must distinguish your voice from dozens of others. Furthermore, “Linguistic Variability”—such as accents, dialects, and slang—can drastically lower accuracy. If a transcription model was only trained on “Standard American English,” it may struggle significantly with a Scottish or Australian accent. This is a major area of research for automated speech recognition developers.
There is also the critical issue of bias in automated speech recognition ai. Studies have shown that some asr systems have higher error rates for certain demographics, particularly people of color and non-native speakers. This happens when the training data is not representative of the global population. Addressing this requires a concerted effort to build more inclusive datasets. For asr technology to be truly universal, it must work equally well for everyone, regardless of where they are from or how they speak.
Real-World Applications of ASR Across Industries
The applications for automatic speech recognition are virtually limitless. In the “Healthcare” sector, asr is used for medical scribing. Doctors can speak their observations and prescriptions directly into an asr system, which automatically updates the patient’s electronic health records. This reduces the administrative burden on medical professionals and allows them to spend more time with patients. Specialized automated speech recognition software in this field is trained to recognize complex pharmaceutical names and anatomical terms with high precision.
In the “Legal” and “Education” sectors, asr transcription is a game-changer. Court reporters use automated speech recognition to assist in creating transcripts of trials, while universities use it to provide real-time captions for lectures. This is essential for compliance with accessibility laws, ensuring that students who are deaf or hard of hearing have equal access to information. By using asr technology, institutions can produce large volumes of text much faster and cheaper than using human transcribers alone.
The “Customer Service” industry is perhaps the largest consumer of speech recognition technology. Modern Interactive Voice Response (IVR) systems use asr to let customers speak their needs rather than pressing buttons on a keypad. Furthermore, many companies use asr software to transcribe and analyze support calls. This allows them to identify common customer complaints and track the performance of their support agents. When paired with sentiment analysis, automatic speech recognition can even tell a manager if a customer is getting frustrated during a call.
The Benefits and Drawbacks of Automated Speech Recognition
The primary benefit of automatic speech recognition is “Efficiency.” Typing is a bottleneck for human thought; most people can speak at 150 words per minute but can only type at 40 to 60. By using asr, individuals can document ideas, write emails, and create reports significantly faster. In a business context, this leads to massive cost savings. For example, a legal firm can use asr transcription to process thousands of hours of depositions in a fraction of the time it would take a human team.
Another major benefit is “Accessibility.” Asr opens the digital world to people with visual impairments, dyslexia, or motor disabilities that make typing difficult. It also facilitates “Multilingual Communication.” Many modern asr systems are integrated with translation engines. This means someone can speak in Spanish, and the system can provide real-time English text. This automated speech recognition ai capability is breaking down language barriers in international business and tourism, making the world a more connected place.
However, there are “Drawbacks” to consider. The first is “Reliability.” In high-stakes environments, a single misinterpreted word by an asr model can have serious consequences. For instance, a medical transcript that confuses “hypo” with “hyper” could lead to a dangerous medication error. Therefore, many industries still require a human “editor” to review the automated speech output. Additionally, there are privacy concerns. Since many asr tools process audio in the cloud, users must trust that the providers are keeping their vocal data secure and not using it for unauthorized purposes.

Research and Facts: The Growth of ASR Technology
The automatic speech recognition market is experiencing explosive growth.
According to a report by Grand View Research, the global speech recognition technology market size was valued at approximately USD 12 billion in 2022 and is expected to grow at a compound annual growth rate (CAGR) of nearly 19% through 2030.
This growth is driven by the increasing adoption of smart speakers, the integration of voice assistants in vehicles, and the rising demand for voice-based authentication in banking and finance.
A fascinating fact regarding asr accuracy is the “Human Parity” milestone. In 2016, researchers at Microsoft announced that their automatic speech recognition system had achieved a WER of 5.9%, which was equal to the error rate of professional human transcribers on the same task. Since then, the numbers have continued to improve. Today, in “clean” audio environments, the best asr model architectures can achieve error rates as low as 2-3%. This research proves that we are moving toward a future where talking to a computer will be just as reliable as talking to a person.
Furthermore, the rise of “Self-Supervised Learning” is a major trend in asr technology research. Traditionally, AI needed humans to label audio data. New models like Meta’s Wav2Vec 2.0 can learn the basic structure of speech just by listening to thousands of hours of unlabeled audio. This allows for the creation of asr software for rare languages where labeled data is scarce. This democratization of speech recognition is one of the most exciting frontiers in modern artificial intelligence.
The Future of ASR: What to Expect Next
The future of automatic speech recognition is deeply intertwined with “Contextual Awareness.” Current systems are getting better at understanding what was said, but the next generation will understand why it was said. By analyzing the speaker’s tone, the surrounding environment, and previous interactions, an asr system will be able to provide much more relevant responses. Imagine a car that recognizes you are stressed based on your voice and automatically adjusts the route to avoid traffic while playing calming music.
We are also seeing a move toward “Unified Models.” Instead of having separate models for asr, translation, and text-to-speech, future AI will likely be multimodal. A single automatic speech recognition ai could handle a conversation in five different languages simultaneously, translating and transcribing everyone in real-time. This will make international conferences and diplomatic meetings more seamless than ever before. The transcription model of the future will not just be a tool for text; it will be a universal interface for human thought.
Finally, the trend of automatic speech recognition on-device will reach its zenith. With the advent of specialized AI chips in everything from watches to smart glasses, we will move toward an “Ambient Computing” world. In this world, the asr system is always there, ready to assist, without the need for a visible screen or keyboard. Your voice will become your primary digital key and command center. As speech recognition technology continues to vanish into the background of our lives, it will ironically become the most important way we interact with the world around us.
Read More: What is Internet Calling: How Internet Calling Works?
Final Thought
Automatic Speech Recognition is a testament to human ingenuity, turning the abstract vibrations of our voices into actionable digital data. From the basic asr meaning of converting sound to text, we have evolved into a society where automatic speech recognition ai manages our calendars, transcribes our surgeries, and assists those with disabilities. While challenges like background noise and linguistic bias remain, the rapid advancement of the asr model and neural network technology suggests these hurdles are temporary. As we refine asr software and move toward more inclusive, on-device processing, the barrier between human intent and machine execution will continue to dissolve. Whether for business efficiency or personal accessibility, speech recognition technology is not just a tool for today; it is the fundamental language of tomorrow’s digital world.
Frequently Asked Questions (FAQs)
-
How accurate is ASR today?
In ideal conditions with clear audio and standard accents, modern automatic speech recognition can achieve accuracy rates of 95% to 98%. This is considered “human parity.” However, accuracy can drop significantly in noisy environments, or when the speaker has a heavy accent or uses niche technical jargon that the transcription model hasn’t been trained on.
-
Can ASR work offline?
Yes, many modern systems utilize automatic speech recognition on-device. This allows the asr software to process your voice locally on your smartphone or computer without an internet connection. This is highly beneficial for privacy and for using voice commands in areas with poor connectivity, though the most complex asr models still often rely on cloud servers for maximum accuracy.
-
What is the difference between ASR and voice assistants?
Asr is the underlying technology that converts spoken words into text. A voice assistant (like Siri or Alexa) is a larger application that uses speech recognition technology. After the asr system transcribes the voice, the voice assistant uses Natural Language Understanding (NLU) to figure out the intent and then performs an action or gives a response.
-
How many languages does ASR support?
The most popular automatic speech recognition software tools support over 100 languages. Major languages like English, Spanish, and Mandarin have the highest accuracy because there is more training data available. However, thanks to new techniques like self-supervised learning, researchers are rapidly developing asr capabilities for hundreds of “low-resource” languages and regional dialects.
-
Is ASR safe for private conversations?
Safety depends on how the asr technology is implemented. If the processing happens on-device, the audio data never leaves your hardware, making it very safe. If the audio is sent to the cloud, its safety depends on the provider’s encryption and data privacy policies. Always check if your asr software provider uses your data for “model training,” which may involve human reviewers listening to audio snippets.